Posters
| Paper ID (AAAI26_Identifier_Paper#) | Paper Title | Authors | Poster ID |
|---|---|---|---|
| AAAI26_W15_2 | Beyond Hallucinations: A Composite Score for Measuring Reliability in Open-Source Large Language Models | Rohit Kumar Salla, Manoj Saravanan, Shrikar Reddy Kota | WS68 |
| AAAI26_W15_4 | Task Interference in VLMs for Autonomous Driving: When Better Perception Hurts Planning | Sai Bhargav Rongali, Aadya Pipersenia, Kenji Okuma | WS69 |
| AAAI26_W15_5 | Quantifying Conversational Reliability of Large Language Models under Multi-Turn Interaction | Jiyoon Myung | WS70 |
| AAAI26_W15_11 | AlignVQA: Debate-Driven Multi-Agent Calibration for Vision Language Models | Ayush Pandey, Jai Bardhan, Ramya S Hebbalaguppe | WS71 |
| AAAI26_W15_12 | Can In-Context Learning Defend against Backdoor Attacks to LLMs | Yonghua Zhu, Qiqi Tao, Na Zhao | WS72 |
| AAAI26_W15_13 | VISOR: Visual Input based Steering for Output Redirection in Large Vision Language Models | Mansi Phute, Ravikumar Balakrishnan | WS73 |
| AAAI26_W15_14 | Layer of Truth: Probing Belief Shifts under Continual Pre-Training Poisoning | Svetlana Churina, Chebrolu Niranjan, Kokil Jaidka | WS74 |
| AAAI26_W15_15 | Beyond Grey-Box Assumptions: Uncertainty-Guided Example Selection for Black-Box Language Models | Egor Krasheninnikov, Zainab Afolabi, Giuseppe Mascellaro | WS75 |
| AAAI26_W15_16 | Smart-GRPO: Smartly Sampling Noise for Efficient RL of Flow-Matching Models | Benjamin Yu, Ziyang Liu, Justin Cui | WS76 |
| AAAI26_W15_18 | Red Teaming Multimodal Language Models: Evaluating Harm Across Prompt Modalities and Models | Madison Van Doren, Casey Ford | WS77 |
| AAAI26_W15_19 | SafeGen: Benchmarking Inference-Time Methods for Privacy-Preserving Text Generation | Aravilli Atchuta Ram | WS78 |
| AAAI26_W15_20 | BLUFF-1000: Measuring Uncertainty Expression in RAG | Ron Zharzhavsky, Emma Wong, Daniel Ketema | WS79 |
| AAAI26_W15_22 | Reasoning Models are Test Exploiters: Rethinking Multiple Choice | Narun Krishnamurthi Raman, Taylor Lundy, Kevin Leyton-Brown | WS80 |
| AAAI26_W15_24 | Optimizing Chain-of-Thought Confidence via Topological and Dirichlet Risk Analysis | Abhishek More, Anthony Zhang, Nicole Bonilla, Ashvik Vivekan, Kevin Zhu, Parham Sharafoleslami, Maheep Chaudhary | WS81 |
| AAAI26_W15_27 | LLMs are Overconfident: Evaluating Confidence Interval Calibration with FermiEval | Elliot L Epstein, John Winnicki, Thanawat Sornwanee, Rajat Vadiraj Dwaraknath | WS82 |
| AAAI26_W15_28 | Know Or Not: a library for systematically evaluating out-of-knowledge-base robustness | Jessica Foo, Pradyumna Shyama Prasad, Shaun Khoo | WS83 |
| AAAI26_W15_29 | Next-Frame Prediction as a Reliability-Aware Training Paradigm for Robust Vision Encoders | Marcel Simon, Eunbin Lee, Tae-Ho Kim, Seul-Ki Yeom | WS84 |
| AAAI26_W15_34 | Beyond Blind Spots: Analytic Hints for Mitigating LLM-Based Evaluation Pitfalls | Ora Nova Fandina, Gal Amram, Eitan Farch, Shmulik Froimovich, Raviv Gal, Wesam Ibraheem, Rami Katan, Alice Podolsky, Orna Raz | WS85 |
| AAAI26_W15_36 | Future Is Unevenly Distributed: Forecasting Ability Of LLMs Depends On What We’re Asking | Chinmay Karkar, Paras Chopra | WS86 |
| AAAI26_W15_38 | Black-Box Uncertainty Quantification for Large Language Models via Ensemble-of-Ensembles | Wang Ma, Debarun Bhattacharya, Junkyu Lee, Nhan H Pham, Harsha Kokel, Qiang Ji | WS87 |
| AAAI26_W15_39 | Prompt-Adaptive Quantization: Adaptive Per-Prompt Routing for Efficient LLM Inference | Gabriel Jimenez, Vivann Khanna, Rishi Sastri, Raine Ma, Soham Chatterjee, Kevin Zhu, Sunischal Dev | WS88 |
| AAAI26_W15_52 | BiPrompt: Bilateral Prompt Optimization for Visual and Textual Debiasing in Vision Language Models | Sunny Gupta, Shounak Das, Amit Sethi | WS89 |
| AAAI26_W15_54 | COMPASS: Context-Modulated PID Attention Steering System for Hallucination Mitigation | Kenji Sahay, Snigdha Pandya, Rohan Nagale, Anna Lin, Shikhar Shiromani, Kevin Zhu, Sunischal Dev | WS90 |
Oral Sessions Schedule:
Presentation 1: Task Interference in VLMs for Autonomous Driving: When Better Perception Hurts Planning
Presenter: Aadya Pipersenia, Honda Japan
Presentation 2: Layer of Truth: Probing Belief Shifts under Continual Pre-Training Poisoning
Presenter: Svetlana Churina, National University of Singapore
Presentation 3: LLMs are Overconfident: Evaluating Confidence Interval Calibration with FermiEval
Presenter: Elliot Epstein, Stanford University
Presentation 4: Next-Frame Prediction as a Reliability-Aware Training Paradigm for Robust Vision Encoders
Presenter: Marcel Simon, Nota AI
Presentation 5: Future Is Unevenly Distributed: Forecasting Ability Of LLMs Depends On What We’re Asking
Presenter: Chinmay Karkar, Lossfunk India
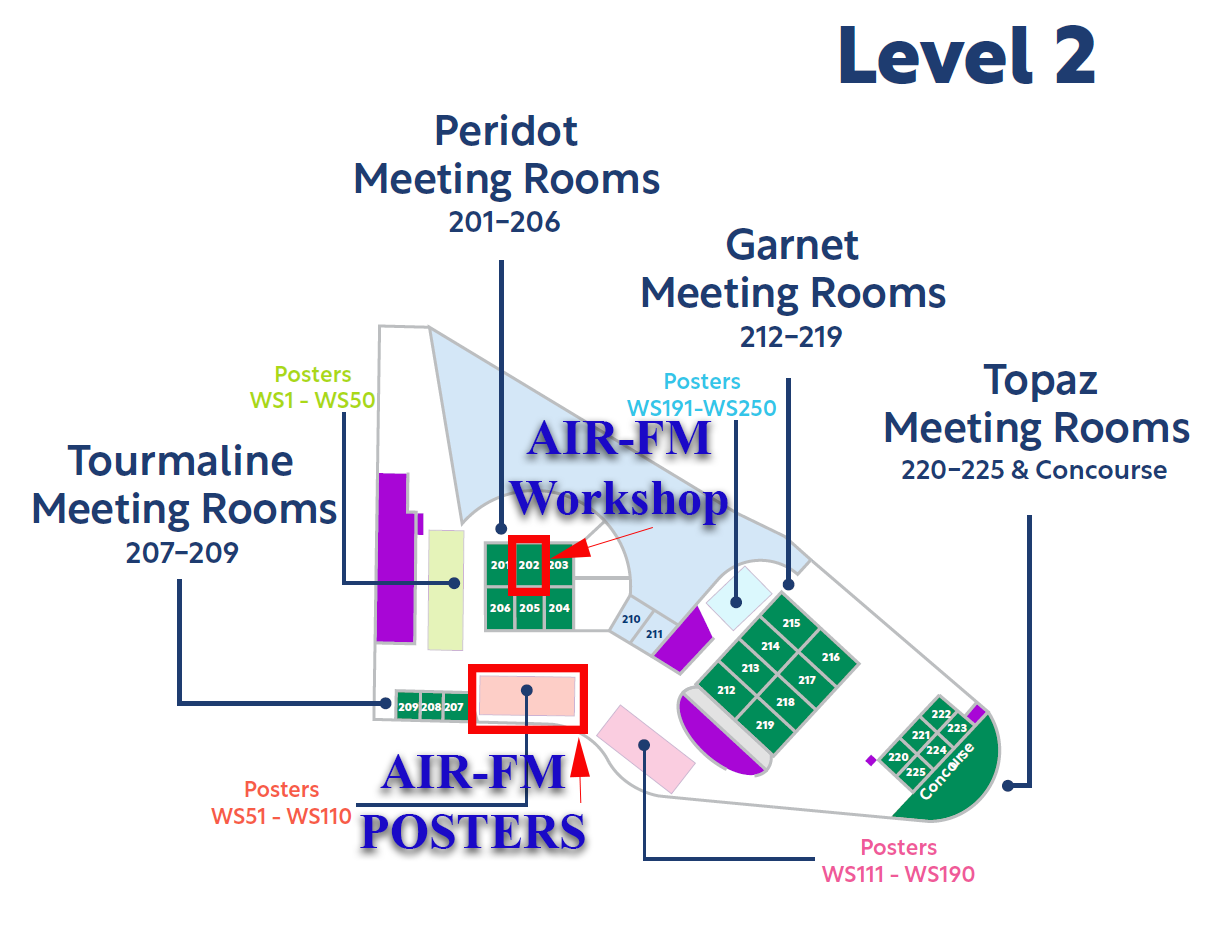
Poster Location and Setup
All posters for Bridges and Workshops will be located on Level 2 of the Singapore EXPO (not in the Expo Halls).
The poster boards are double-sided and arranged in an accordion formation. Each poster board will have a number displayed on it (e.g., WS68, WS69, WS70, …).
Material required to put up the poster will be provided by AAAI.
Presenter Guidelines:
- Use size A0 posters in portrait orientation - fastening materials will be provided
- Display their posters on the day of their poster session - not the evening before.
- Remove their posters at the end of the poster session to prevent loss
- AAAI is not responsible for posters that are misplaced or stolen